
组网及说明
一、背景知识
1、所有V7的安全硬件设备(不包括-V这种部署在服务器上的虚拟设备),在运行流量转发、nat、LB、VPN、安全策略等功能时都需要消耗设备的CPU硬件资源,这就会导致大流量的情况下,CPU占用率较高。
2、防火墙单CPU(盒子设备一般就一颗CPU,分布式设备一般一块板卡一颗CPU或一个子卡一颗CPU)目前在网的大部分型号都是非X86的,一颗CPU会虚拟出多个VCPU,俗称单核。
3、流量上墙后如果要上CPU处理,默认的是根据源地址hash上到某一个单核处理,即源地址相同的流都上到同一个单核处理。cpu核心分为控制核与转发核。以下图为M9K为例,为48核(前4为控制核,后44为转发核,转发业业务在转发核处理):
如上图,一个cpu虚拟出48个核,单核最大承担数=本板卡吞吐/48,单核的最大占比约为2.1%左右(会有抢占的情况,故也会存在占比稍超过2.1%情况)。
告警信息
当单核高的时候会有一下日志伴随打印:
%Jun 26 09:20:55:596 2026 xx/1/CORE_EXCEED_THRESHOLD: -Slot=2.1; Usage of CPU 1 core 45 exceeded the threshold (95%).//单核阈值超过95%
%Jun 26 09:22:00:276 2026 xx/5/CORE_RECOVERY: -Slot=2.1; Core usage alarm CPU 1 core 45 removed. //单核阈值恢复
问题描述
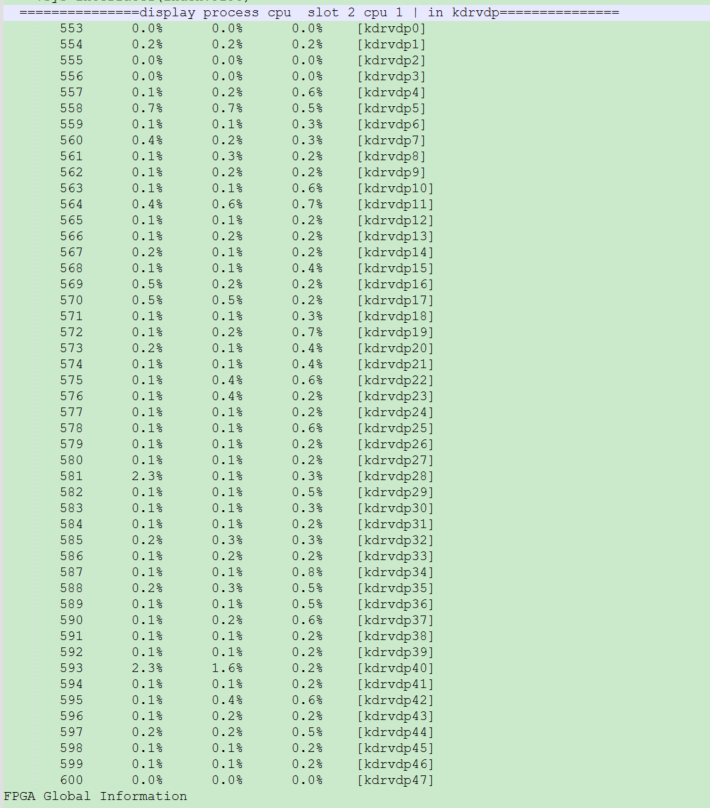
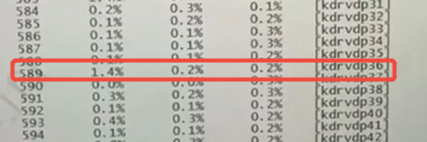
查看此时设备的kdrv情况(例如下图,5s内单核达到1.4%,但1min、5min都0.2%,说明存在飘高现象,不是持续性高),查看的方式参考背景知识中命令
当单核偏高时候,最常见的原因包含但是不限于以下方式:
1、设备新建流量大,包括正常突发,大象流突发、异常攻击等
2、如果是高端设备存在逻辑情况时候,逻辑无会话引发流量全部上CPU处理。具体参考 https://zhiliao.h3c.com/Theme/details/182583
3、 由于开启dpi、二层(vlan-if)、会话引流等,压低了本身可承载流量
上述原因归纳出主要原因就是(1)CPU正常时候,但是处理的流量增大了,或者(2)CPU的处理能力下降,正常流量引发CPU负荷过载。
本着以上的原因排查过程如下过程分析
过程分析
一、单核故障持续存在。
1、查看此时的会话统计信息:display session statistics summary
这种方式可以判断目前设备的新建+并发数情况,对比正常时候的诊断就会得知目前的流量是不是徒增了
(例如会话打到了40W,可能是多个流量都偏高,若8w这种,可能是单个流量偏高,酌情自行判断)
2、查看近一个时间段内的会话数(排名统计开关一下再去查看回显,主要看是否有某些异常流量会话迅速增长,因top统计是累加值,故需要重新开关):
undo session top-statistics enable
session top-statistics enable
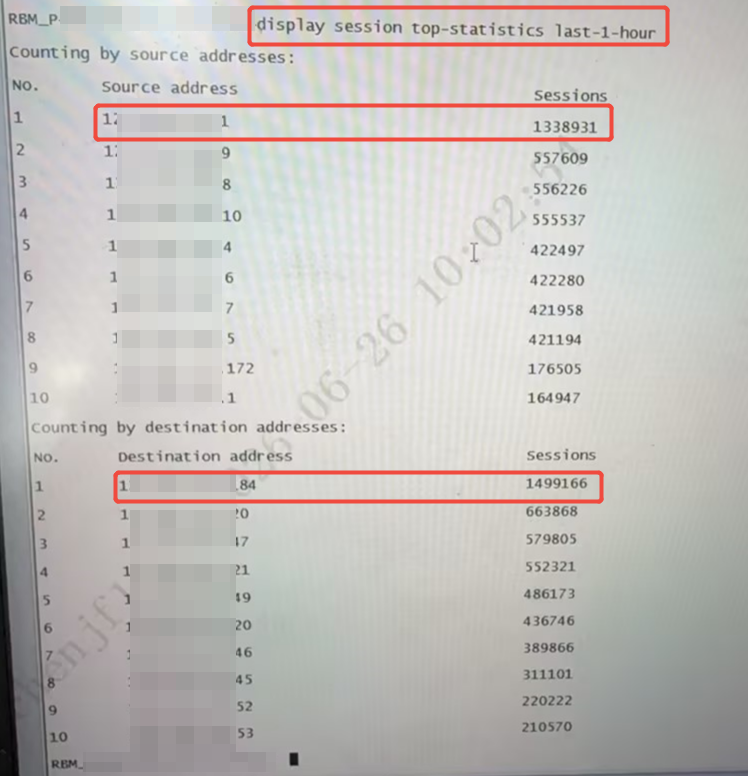
3、前面两点可以找到了会话增高的对应ip(多找几个ip都看下),display session table sou ip +上面的回显比较突出的 (ver)可以看到具体的会话,便于现场确认具体业务。
如若大量会话状态为SYN_SENT、SYN_RCVD,TCP_CLOSE,等等之类的,这种会话设备上不会大量存在,反推这种IP一定是异常的,大概率是存在异常流量攻击,或者扫描类的流量,建议客户排查IP并阻断。
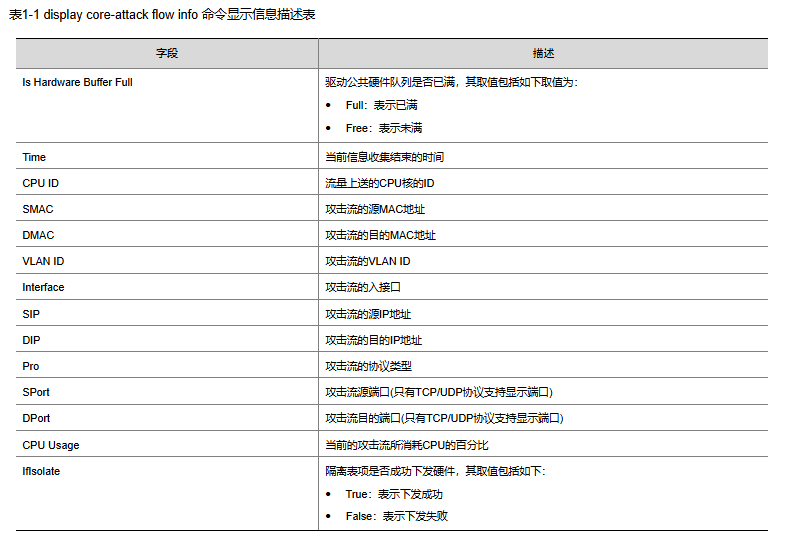
4、直接查看单核占用的记录,display attack-defense cpu-core flow info chassis X slot Y cpu 1 (X=框号,Y=槽位号)查看对应板卡处理的攻击流量(中高低端新版本都支持该命令)。
例如现场的回显,可以看到源目ip对应的流量消耗的cpu高达97%,和现场明确该对应业务类型及是否正常。若为异常流量请及时进行阻断等规避措施。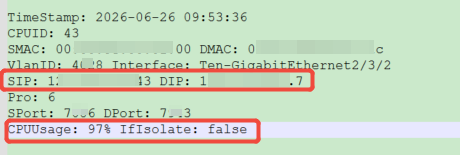
5、可以修改接口的flow-interval时间为5s,然后查看
display counters rate inbound interface和
display counters rate outbound interface
是不是设备存在大量的广播和组播
6、在不得已的情况下,可以基于抓包排查单位时间内哪些报文占比整网的流量大,或者发包速度快,大概率就是引发单核高的五元组 (某一单核高,但top-session没有特别突出的,可以单核抓包进一步判断)。
注:中低端web全局抓包,高端设备需要基于单核抓包,抓包脚本请联系400获取。
二、故障不定时出现,且无故障时环境。
1、确认客户侧是否存在监控平台或NDR设备等,查看异常时间段是否存在异常流量,以及是否上送接口,确认是不是存在故障时间点前后接口流量突增,流量增大情况;
2、查看如下命令有没有记录 display attack-defense cpu-core flow info chassis X slot Y cpu 1
3、手工配置一个EAA脚本实现自动化监控,待故障复现收集信息分析(高端设备,中低端web抓包)。
脚本内容也同步查看:cpu、kdrv、内存、接口流量(统计周期改为5s)、会话量。
可参考:https://zhiliao.h3c.com/Theme/details/219268
注:不定时偏高大概率原因和上述的所有情况是一致的,因为不定时无法准确固定去五元组,所以定位相对困难。
解决方法
总结就是某一条或几条流量非常大导致单核被占满。排查问题的主要思路就是找到影响单核的流量信息。与现场确认并判断是否是异常流量,如果是异常流量,建议在上行设备配置阻断(防火墙上配置阻断需要消耗CPU算力,效果可能不明显),如果是正常流量在具体判断是否可以开启逐包转发等。
如果找到了异常高流量,但均属于正常业务流量,如何优化?
1、不让该流量上送设备(调整流量走向);
2、对该部分业务流量限速;
3、关闭DPI;
4、开启逐包;
5、配置攻击防范动作。

该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作